系统工程手册(Systems Engineering Handbook)是国际系统工程协会(INCOSE)编著的一本权威性指导书籍,旨在为系统工程的全生命周期过程和活动提供详细的指南,其内容基本涵盖ISO/IEC/IEEE 15288(系统生命周期过程)和ISO/IEC/IEEE 26771(系统工程管理计划)。这些标准为系统工程的全生命周期提供了清晰的指导,涵盖了需求分析、设计、开发、测试和维护等环节,帮助工程师高效管理复杂项目,确保系统从概念到退役的全过程都能科学运作。
为了方便感兴趣的人士参考,reddish(@srs.pub)基于系统工程手册第四版(2015),借助通义完成翻译,并做校稿,个别地方有做必要的修正和裁剪。
本文是的中文译本的第十章专业工程活动(Specialty Enginerring Activities)的第八小节:可靠性、可用性和可维护性(Reliablity, Avaialability, Maintainablity)。
1 可靠性、可用性和可维护性
为了可靠,一个系统必须是健壮的——即使在恶劣环境、变化的操作需求和内部恶化等广泛条件下,它也必须避免故障模式(Clausing 和 Frey,2005)。因此,可靠性可以被视为系统在其预期寿命期间,在现场经历的各种条件下正常运行的能力。
可靠性工程是指在系统整个生命周期内解决系统可靠性的专门工程学科。它包括系统的可用性和可维护性等相关方面。因此,可靠性工程通常被用作与系统RAM相关的工程学科的总称。
RAM是给定系统的重要属性或特征。然而,RAM实际上不应被视为特征,而应被视为非功能性需求。因此,SE过程必须包括RAM活动,并与其他技术过程以集成的方式进行选择、规划和执行。
可靠性工程活动以两种方式支持其他系统工程过程。首先,应使用可靠性工程活动来影响系统设计(例如,系统架构取决于可靠性要求)。其次,应将可靠性工程活动作为系统验证的一部分(例如,系统分析或系统测试)。
2 可靠性
可靠性工程的目标,按优先顺序排列为(O’Connor和Kleyner,2012):
- 应用工程知识和专业技能来预防或减少故障的可能性或频率
- 识别并纠正尽管努力预防但仍发生的故障的原因
- 确定应对已发生故障的方法,如果其原因尚未得到纠正
- 应用方法来估计新设计的可能可靠性并分析可靠性数据
优先重点是重要的,因为主动预防故障总是比被动纠正故障更具成本效益。及时执行适当的可靠性工程活动对于在操作过程中实现所需的可靠性至关重要。
传统上,可靠性被定义为在规定条件下,在规定时间内,物品无故障执行所需功能的概率(O’Connor和Kleyner,2012)。可靠性定义中对概率的强调(以量化可靠性)导致了一些可能误导甚至错误的做法(例如,电子系统的可靠性预测和可靠性演示)。
现代的可靠性方法更加强调在系统预期寿命期间防止故障所需的工程过程(即无故障操作)。最近,“设计可靠性的概念”已经从被动的“测试 - 分析 - 修复”方法转向主动地将可靠性设计到系统中的方法。“故障模式避免”方法与其他SE过程一致,并试图在早期提高系统的可靠性。发展阶段(Clausing和Frey,2005)。它通过评估系统功能、技术成熟度、系统架构、冗余、设计选项等潜在故障模式来执行。在系统可靠性方面,最显著的改进可以通过首先避免物理故障模式来实现,而不是在系统构思、设计和生产后进行微小的改进。
“设计可靠性”意味着可靠性应该被指定为一个要求,以便在需求分析过程中得到足够的关注。可靠性要求可以以定性或定量的方式指定,具体取决于特定的行业。需要注意的是,由于可靠性验证通常不切实际(特别是对于高可靠性要求),因此应谨慎对待定量要求。此外,滥用可靠性指标(例如平均故障间隔时间(MTBF))经常导致在系统开发过程中“玩数字游戏”,而不是专注于实现可靠性的工程努力(Barnard,2008)。例如,MTBF通常被用作“平均寿命”的指标,这可能是完全错误的。因此,建议使用其他可靠性指标来制定定量要求(例如,在特定时间的可靠性(作为成功概率))。
2.1 可靠性计划的制定
在系统开发过程中,可靠性工程活动常常被忽视,导致项目失败或客户不满的风险大幅增加。因此,建议将可靠性工程活动正式整合到其他SE技术流程中。实现整合的一个实用方法是在项目开始时制定一个可靠性计划。
应根据具体项目的目选择和定制适当的可靠性工程活动。这些活动应在可靠性计划中体现。该计划应说明将执行哪些活动、活动的计划时间、活动所需的详细程度以及负责执行活动的人员。
ANSI/GEIA - STD - 0009 - 2008,系统设计、开发和制造的可靠性程序标准,可以为此目的作为参考。该标准不仅涉及硬件和软件故障,还涉及其他常见故障原因,如制造、操作员错误、操作员维护、培训、质量等。等等。“标准的核心是一个系统性的‘设计可靠性’过程,其中包括三个要素:
- 对系统级操作和环境负载的逐步理解,以及由此在整个系统结构中产生的负载和应力。
- 逐步识别由此产生的故障模式和机制。
- 积极缓解已发现的故障模式。
ANSI/GEIA - STD - 0009 - 2008支持可靠性工程的系统生命周期方法,包括以下目标:
- 了解客户/用户的需求和限制。
- 为可靠性进行设计和重新设计。
- 生产可靠系统/产品。
- 监控和评估用户可靠性。
因此,可靠性计划提供了如何实现可靠性目标的前瞻性观点。与可靠性计划相辅相成的是可靠性案例,它提供了系统生命周期中已实现目标的回顾性(和记录)视图。
图10.8显示了一些相关问题,这些问题可用于为特定项目制定可靠性计划。
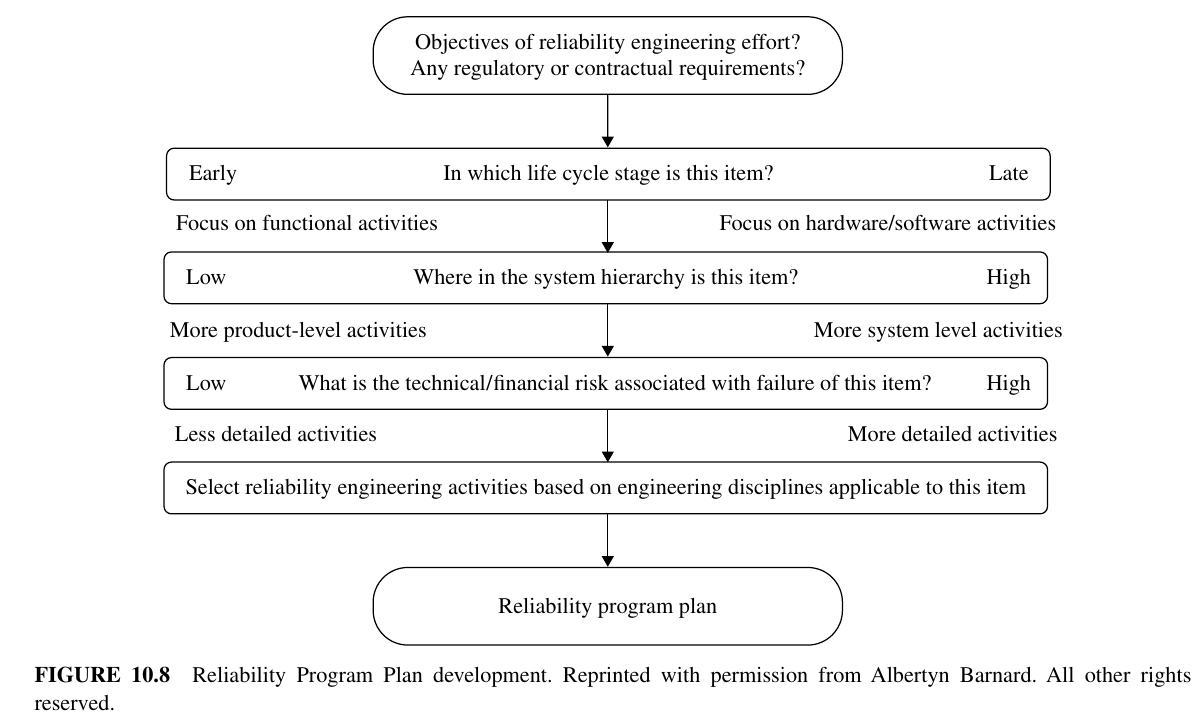
2.2 可靠性工程活动
可靠性工程活动可以分为两组,即工程分析和测试以及故障分析。这些活动由各种可靠性管理活动支持(例如,设计程序、设计清单、设计审查、电子部件降额指南、优选部件清单、优选供应商清单等)。
工程分析和测试指的是传统的设计分析和测试方法,例如在设计过程中进行的载荷 - 强度分析。这一组包括有限元分析、振动和冲击分析、热分析和测量、电气应力分析、磨损寿命预测、高度加速寿命测试(HALT)等。
故障分析是指传统的RAM分析,以提高对因果关系的理解。在设计和操作过程中,这一组包括失效模式与影响分析(FMEA)、故障树分析(FTA)、可靠性框图分析(RBD)、系统建模与仿真、根本原因失效分析等。
3 可用性
可用性被定义为在规定条件下使用时,系统在任何时间点都能按要求正常运行的概率。因此,可用性取决于系统的可靠性和可维护性,以及在使用和支持阶段的支持环境。它可以用固有可用性、实现可用性或操作可用性来表示和定义(Blanchard 和 Fabrycky,2011):
- 内在可用性(A i):仅基于系统的内在可靠性和可维护性。它假设了一个理想的支持环境(例如,随时可用的工具、备件和维护人员),并排除了预防性维护、物流延迟时间和行政延迟时间。
- 实现的可用性(A a):与固有可用性相似,但包括预防性(即计划性)维护。它不包括物流延迟时间和行政延迟时间。
- 运营可用性(A o):假设了一个实际的运营环境,因此包括了物流延迟时间和行政延迟时间。
4 可维护性
系统工程的目标是设计和开发一个系统,该系统能够在最短的时间内、以最低的成本和最少的支持资源进行有效、安全的维护,同时不会对系统的任务产生不利影响。可维护性是指系统能够被维护的能力,而维护则是一系列为恢复或保持系统有效运行状态而采取的行动。可维护性必须是固有的或“内置”在设计中的,而维护则是设计的结果。
可维护性可以用维护时间、维护频率因素和维护劳动时间,以及维护成本来表示。维护可以分为纠正性维护(即,由于故障而完成的非计划性维护,以将系统恢复到指定的性能水平)和预防性维护(即,通过提供系统的检查和维修或通过定期更换项目来防止即将发生的故障,以保持系统在指定的性能水平)(Blanchard 和 Fabrycky,2011)。
5 与其他工程学科的关系
可靠性工程与其它工程学科密切相关,如安全工程和物流工程。可靠性工程的主要目标是防止故障。安全工程的主要目标是在正常和异常条件下预防和减轻伤害(见第10.10节)。物流工程的主要目标是开发高效的物流支持(例如,预防性和纠正性维护;见第10.5节)。
这三个学科不仅有“失败”作为共同的主题,而且它们也可能使用类似的活动,尽管是从不同的角度。例如,FMEA可能适用于可靠性、安全性和物流工程。然而,由于目标不同,设计FMEA将不同于安全或物流FMEA。所有学科的共同点是在系统生命周期早期实施的必要性。
虽然可靠性关注的是故障(或者更确切地说是无故障),但可维护性指的是系统能够被维护的能力(或维护的容易程度)。可用性是可靠性和可维护性的函数,可能包括后勤方面(如操作可用性的情况)。系统的生命周期成本高度依赖于可靠性和可维护性,它们被认为是支持资源和相关在役成本的主要驱动因素。